
-
PiFlow(大数据流水线系统) v0.9官方版
大小:302M语言:英文 类别:其他行业系统:WinAll
标签: PiFlow(大数据流水线系统)
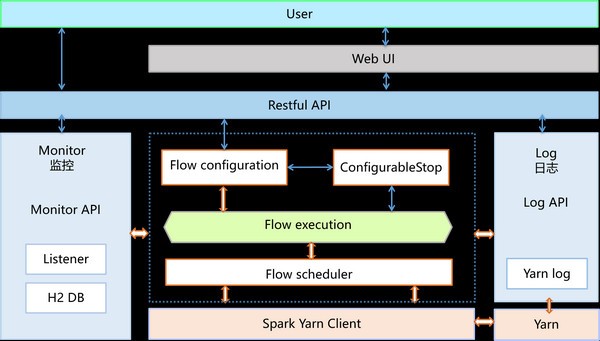
PiFlow是一个简单易用,功能强大的大数据流水线系统,混合型科学大数据流水线系统,包含丰富的处理器组件,提供Shell、DSL、Web配置界面、任务调度、任务监控等功能!
简单易用
可视化配置流水线
监控流水线
查看流水线日志
检查点功能
扩展性强:
支持自定义开发数据处理组件
性能优越:
基于分布式计算引擎Spark开发
功能强大:
提供100+的数据处理组件
包括Hadoop 、Spark、MLlib、Hive、Solr、Redis、MemCache、ElasticSearch、JDBC、MongoDB、HTTP、FTP、XML、CSV、JSON等
集成了微生物领域的相关算法
使用方法解压piflow-server-v0.9.tar.gz:
tar -zxvf piflow-server-v0.9.tar.gz
编辑配置文件config.properties
运行、停止、重启PiFlow Server
start.sh、stop.sh、 restart.sh、 status.sh
测试 PiFlow Server
设置环境变量 PIFLOW_HOME
vim /etc/profile
export PIFLOW_HOME=/yourPiflowPath/bin
export PATH=PATH:PIFLOW_HOME/bin
运行如下命令
piflow flow start example/mockDataFlow.json
piflow flow stop appID
piflow flow info appID
piflow flow log appID
piflow flowGroup start example/mockDataGroup.json
piflow flowGroup stop groupId
piflow flowGroup info groupId
如何配置config.properties
#spark and yarn config
spark.master=yarn
spark.deploy.mode=cluster
#hdfs default file system
fs.defaultFS=hdfs://10.0.86.191:9000
#yarn resourcemanager.hostname
yarn.resourcemanager.hostname=10.0.86.191
#if you want to use hive, set hive metastore uris
#hive.metastore.uris=thrift://10.0.88.71:9083
#show data in log, set 0 if you do not want to show data in logs
data.show=10
#server port
server.port=8002
#h2db port
h2.port=50002
加载全部内容
 modelsim破解版-modelsim se仿真软件下载 v10.1c免费版
modelsim破解版-modelsim se仿真软件下载 v10.1c免费版 led control图文管理系统-led control system下载 v6.4.3.124免费版
led control图文管理系统-led control system下载 v6.4.3.124免费版 兴华加气站管理系统-兴华加气站管理系统下载 v7.8官方版
兴华加气站管理系统-兴华加气站管理系统下载 v7.8官方版 Altair ElectroFlo(热分析软件)下载 v2018免费版
Altair ElectroFlo(热分析软件)下载 v2018免费版 越客美容美发管理系统-越客美容美发管理系统下载 v15.11.06官方版
越客美容美发管理系统-越客美容美发管理系统下载 v15.11.06官方版 种子公司管理系统下载 v1.0官方版
种子公司管理系统下载 v1.0官方版 DC Color-DC-Color(可编程LED控制器)下载 v1.08官方版
DC Color-DC-Color(可编程LED控制器)下载 v1.08官方版 人证合一酒店访客登记管理系统软件下载 v35.3.3官方版
人证合一酒店访客登记管理系统软件下载 v35.3.3官方版 智方客户信息管理系统-智方客户信息管理系统下载 v7.0官方版
智方客户信息管理系统-智方客户信息管理系统下载 v7.0官方版 Kystar Control System(凯视达控制系统)下载 v21.07.09.4288官方版
Kystar Control System(凯视达控制系统)下载 v21.07.09.4288官方版
消防设施操作员3D实操平台-消防设施操作员电脑版下载 v2.2.0官方版347.6M328人在玩消防设施操作员电脑版是一款功能强大,出色优秀的消防教育学习软件,该软件为用户提供了海量优质的消防学习资源,帮助您线上学习,同时还提供课后练习功能,以此来加强巩固所学内容。
下载
百度CarLife车机版-百度CarLife WinCE版下载 v3.1.0.0官方版15.4M320人在玩百度CarLife是百度官方推出的车载导航系统,这是百度CarLifeWinCE车机版安装包,适用于WinCE车载导航系统使用,使用前需准备好导航SD卡将SD卡插入电脑,可配合移动端APP连接使用。
下载
精雕软件(JDpaint)下载 v5.5.0.0免费版-精雕软件5.5破解版下载41.4M224人在玩JDPaint是精雕科技多年来一直致力研制开发的、具有自主版权的、功能强大的专业雕刻CAD/CAM软件,JDPaint是精雕CNC数控雕刻系统正常运作的保证,也能有效提高CNC雕刻系统使用效率。
下载
飒特红外报告分析软件-飒特红外报告分析软件(SatIrReport)下载 v2.6.3官方版178M159人在玩飒特红外报告分析软件,飒特红外智能监控系统为电力、化工、石化、煤炭、护林、制造(易燃产品)、仓储等行业提供了高效、可靠、实时的设备热故障防范、防火、安防等网络在线监测工具。红外智能监控系统可以固定安装或移动工作站形式,实现对目标的不间断或定期的监测和设备的控制,飒特红外智能监控系统可支持飒特CK系列红外监控产品。
下载
京麦工作台-京麦工作台下载 v9.12.0官方版299.2M92人在玩京麦工作台是京东商城为京东的商家准备的一款后台管理工具,京麦工作台支持订单批量出库、批量打印发货单、快递单模板的可定制化、批量打印快递单,针对某些快递单还能自动生成运单号。
下载
Cytospace-Cytospace(网络分析软件)下载 v3.8.0官方版266M80人在玩Cytospace是一个用于复杂网络分析的开源网络的软件,可帮助用户集成,分析和可视化数据,它支持多种网络描述格式,也可以用以Tab制表符分隔的文本文档或MicrosoftExcel文件作为输入,或者利用软件本身的编辑器模块直接构建网络。
下载
云立方虚拟实训中心-云立方虚拟实训中心下载 v2.0官方版121M61人在玩云立方虚拟实训中心是云立方推出的虚拟仿真训练软件,让学生自适应实操训练,同时包含教师端和学生端以及管理员端,教室可以通过平台进行实训课堂的备课。
下载
tr天正电气破解版-TR天正电气软件下载 v5.0官方版1.38G45人在玩TR天正电气软件是三维BIM辅助设计软件。软件一共分为14个部分,每一个部分均按照设计师的设计流程来组织软件功能,将专业化和BIM平台智能化紧密结合,有效的降低了设计人员采用BIM平台进行设计的难度。
下载
HD2020软件-HD2020(单双色控制软件)下载 v1.2.0.6官方版115.9M38人在玩HD2020单双色控制软件是一款新版的单双色控制软件,功能强大,适合灰度旗下的多款控制卡,轻松连接并使用,界面简洁美观,操作简单,既方便又实用。
下载
宝马工时查询软件(BMW KSD)下载 v19.09.1.0官方免费版1.46G37人在玩BMWKSD宝马维修工时查询软件中文版,用于确定工时,检验表和服务的宝贵数据的集合软件,还有关于各种型号的车轮和轮辋的信息。
下载 CodeFun(UI设计稿智能生成源代码软件)下载 v0.4.3官方版
CodeFun(UI设计稿智能生成源代码软件)下载 v0.4.3官方版 律鲸律师-律鲸律师下载 v1.2.4官方版
律鲸律师-律鲸律师下载 v1.2.4官方版 雷电云手机PC版-雷电云手机PC版下载 v1.18.2官方版
雷电云手机PC版-雷电云手机PC版下载 v1.18.2官方版 包租婆农贸市场综合管理系统-包租婆农贸市场综合管理系统下载 v11.2.3.1官方版
包租婆农贸市场综合管理系统-包租婆农贸市场综合管理系统下载 v11.2.3.1官方版 office办公软件
office办公软件 爱奇艺
爱奇艺 网盘下载
网盘下载 电脑投屏软件
电脑投屏软件 oa办公系统
oa办公系统 浏览器
浏览器 直播课堂软件
直播课堂软件